


 DeepFlow Architecture
DeepFlow Architecture
This document was translated by ChatGPT
#1. Software Architecture
DeepFlow primarily consists of two components: Agent and Server. The Agent runs in various environments such as Serverless Pods, K8s Nodes, cloud servers, and virtualized hosts, collecting observability data from all application processes in these environments. The Server runs in a K8s cluster, providing services such as Agent management, data tagging injection, data writing, and data querying.

DeepFlow Community Edition Software Architecture
The enterprise edition of DeepFlow includes more software components to offer more comprehensive data analysis, full-stack and multi-region data management, alert management, report management, dashboard management, and tenant management capabilities.
#2. Design Philosophy
The name DeepFlow reflects our understanding of achieving observability: deep insights into every application call (Flow). All observability data in DeepFlow is organized around calls: raw call logs, aggregated application performance metrics and universal service maps, correlated distributed tracing flame graphs, and network performance metrics, file read/write performance metrics, and function call stack profiling within each call lifecycle. We recognize the challenges in collecting and correlating these observability data and use eBPF technology to achieve zero-intrusion (Zero Code) data collection, and employ SmartEncoding mechanisms to achieve full-stack correlation of all data.

DeepFlow Zero-Intrusion Full-Stack Data Collection Based on eBPF Technology
In addition to zero-intrusion data collection using eBPF technology, DeepFlow also supports integration with mainstream observability technology stacks, such as serving as a storage backend for Prometheus, OpenTelemetry, SkyWalking, Pyroscope, and providing SQL, PromQL, OTLP Export capabilities as data sources for Grafana, Prometheus, OpenTelemetry, SkyWalking, enabling developers to quickly integrate it into their own observability solutions. When serving as a storage backend, DeepFlow does more than just store data; it uses leading AutoTagging and SmartEncoding mechanisms to automatically and efficiently inject unified attribute tags into all observability signals, eliminating data silos and enhancing data drill-down capabilities.
#3. DeepFlow Agent
The DeepFlow Agent is implemented in Rust, offering extreme processing performance and memory safety.
The data collected by the Agent includes the following three categories:
- eBPF Observability Signals
- AutoMetrics
- Collects full-stack RED golden metrics for all services based on eBPF (Linux Kernel 4.14+)
- Collects full-stack RED golden metrics and network performance metrics for all services based on cBPF (Linux Kernel 2.6+), Winpcap (Windows 2008+)
- AutoTracing
- Analyzes the correlation of Raw Request data based on eBPF (Linux Kernel 4.14+), calculating distributed call chains
- Uses cBPF (Linux Kernel 2.6+) data and writes Wasm Plugin to parse business serial numbers to correlate Raw Request data, calculating distributed call chains
- AutoProfiling
- Collects function-level continuous profiling data based on eBPF (Linux Kernel 4.9+) and automatically correlates it with distributed tracing data
- Analyzes network packet timing based on cBPF (Linux Kernel 2.6+), Winpcap (Windows 2008+), generating network performance profiling data to infer application performance bottlenecks
- AutoMetrics
- Instrumentation Observability Signals: Collects observability data from mainstream open-source Agents and SDKs, such as Prometheus, OpenTelemetry, SkyWalking, Pyroscope, etc.
- Tag Data: Synchronizes resource and service information from cloud APIs, K8s apiserver, and CMDB to inject unified tags into all observability signals
Additionally, the Agent supports providing programmable interfaces to developers based on WASM, for parsing application protocols not yet recognized by the Agent and building business analysis capabilities for specific scenarios.
The Agent supports running in various workload environments:
- Runs as a process on Linux/Windows servers, collecting observability data from all processes on the server
- Runs as an independent Pod on each K8s Node, collecting observability data from all Pods on the K8s Node
- Runs as a Sidecar on each K8s Pod, collecting observability data from all Containers in the Pod
- Runs as a process on Android terminal device operating systems, collecting observability data from all processes on the terminal device
- Runs as a process on hosts like KVM, Hyper-V, collecting observability data from all virtual machines
- Runs as a process on dedicated virtual machines, collecting and analyzing mirrored network traffic from VMware VSS/VDS
- Runs as a process on dedicated physical machines, collecting and analyzing mirrored network traffic from physical switches
#4. DeepFlow Server
The DeepFlow Server is implemented in Golang and consists of modules such as Controller, Labeler, Ingester, and Querier:
- Controller: Manages Agents, balances and schedules the communication relationship between Agents and Servers, and synchronizes Tag data collected by Agents.
- Labeler: Calculates unified attribute tags for all observability signals.
- Ingester: Stores observability data in ClickHouse and exports observability data to otel-collector.
- Querier: Queries observability data, providing a unified SQL/PromQL interface to query all types of observability data.
DeepFlow's tag injection mechanism has two features:
- AutoTagging: Automatically injects unified attribute tags into all observability data, including cloud resource attributes, container resource attributes, K8s Label/Annotation/Env, business attributes in CMDB, etc., eliminating data silos and enhancing data drill-down capabilities.
- SmartEncoding: Injects only a small number of pre-encoded meta tags into the data, with most other tags (Custom Tags) stored separately from the observability signals. Through an automatic correlation query mechanism, users experience direct querying on a BigTable. Actual operational data in production environments show that SmartEncoding can reduce tag storage overhead by an order of magnitude.
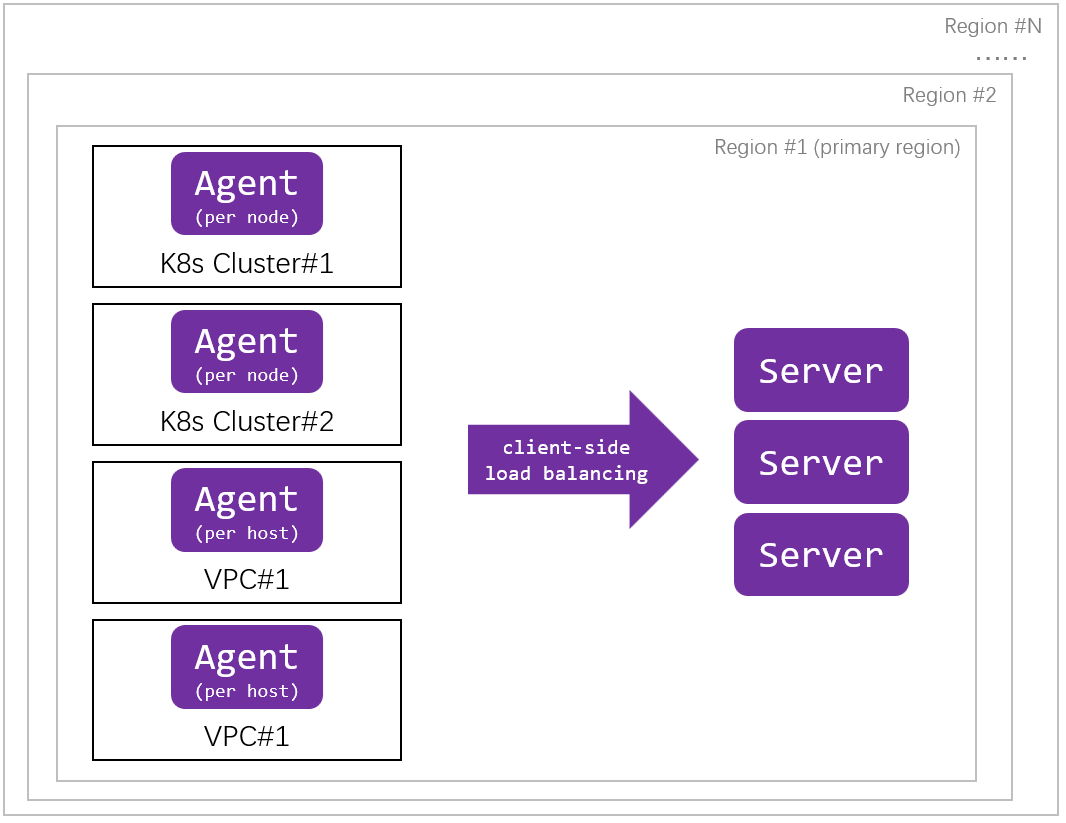
Multi-Cluster and Multi-Region Management Capabilities of the Server
The DeepFlow Server runs as Pods in a K8s cluster, supporting horizontal scaling. The Server cluster can automatically balance and schedule the communication relationship between Agents and Servers based on the data from Agents. A Server cluster can manage Agents in multiple heterogeneous resource pools. The enterprise edition supports unified management across multiple regions.